Chaînes de caractères 
Caractères¶
Un caractère est un symbole. Par exemple, a, E, 1 et ! sont des caractères.
Le type utilisé en C pour stocker un caractère est char :
char c = 'a';
'a' est une valeur, contrairement à c qui est ici une variable.
Remarque : Contrairement à Python qui utilise " et ' de manière interchangeable et qui ne fait pas de distinction entre caractère et chaine de caractères, en C les caractères doivent utiliser ' (et les chaînes de caractères doivent utiliser ").
Sur un ordinateur, il n'est possible de stocker que des 0 et des 1. Il est donc nécessaire de coder les caractères en binaire, par un codage.
Le codage utilisé par défaut en C est ASCII. Il code chaque caractère sur 7 bits. Comme la plus petite unité adressable de mémoire est 1 octet (8 bits), un char est en fait codé sur 8 bits avec un bit non utilisé :
sizeof(c) // un char prend 1 octet, soit 8 bits, en mémoire
1
Comme il y a $2^7$ valeurs possibles sur $7$ bits, ASCII permet de stocker $2^7 = 128$ caractères. Les voici, avec leurs codages :
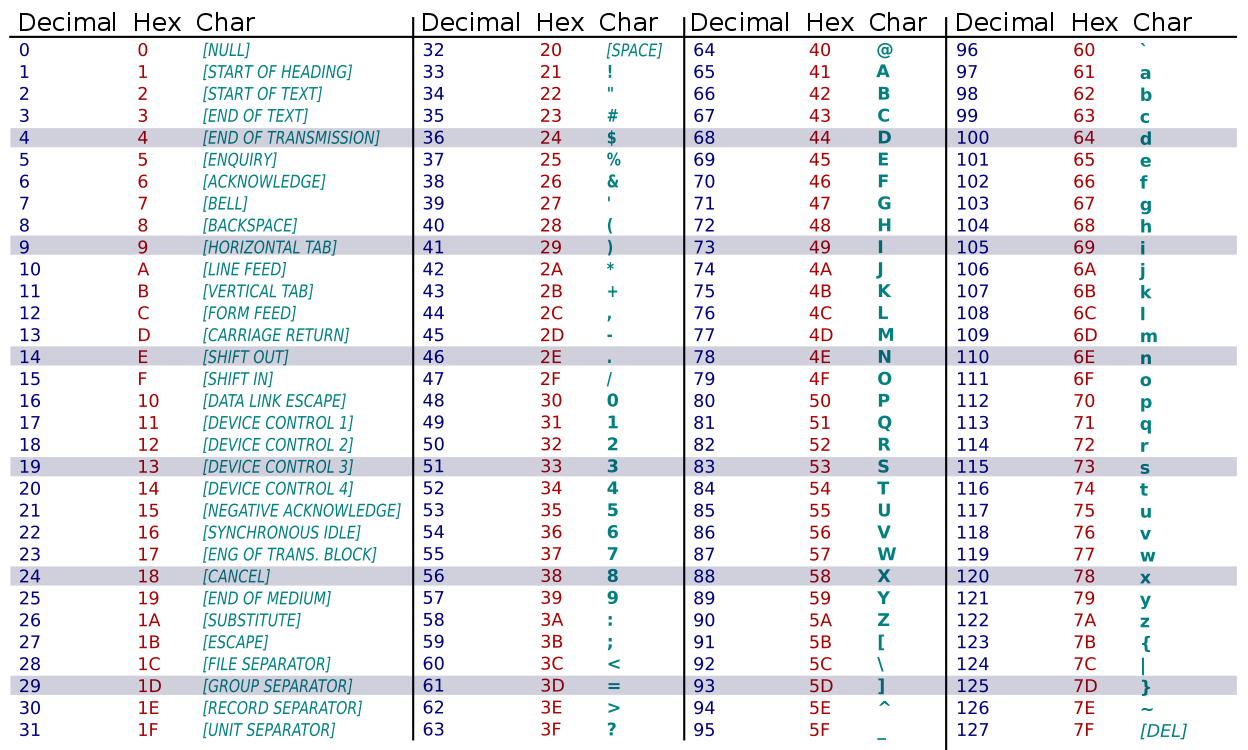
Par exemple, A est codé par 65, c'est-à-dire stocké avec $1000001_2$ en mémoire. On peut le vérifier en convertissant un char en unsigned :
(unsigned)'A'
65
Exercice
Afficher les lettres de l'alphabet. On pourra utiliser un entier dans un for et le convertir en char.
ASCII est très limité. Il ne permet pas d'encoder les accents, par exemple :
char c = 'é'
input_line_13:2:11: error: character too large for enclosing character literal type
char c = 'é'
^
Interpreter Error:
Unicode et UTF-8 sont des normes d'encodages plus modernes et maintenant beaucoup plus utilisées que ASCII :
- Unicode est une table de caractères : à chaque caractère (144697 au total) est associé un entier
- UTF-8 est un encodage pour Unicode : il spécifie comment coder les entiers (correspondants aux caractères Unicode) comme suite de bits, en utilisant un ou plusieurs
char.
Unicode et UTF-8 sont rétro-compatibles avec ASCII (les caractères ASCII garde le même codage).
Voici la proportion des tables de caractères les plus utilisées sur le Web :
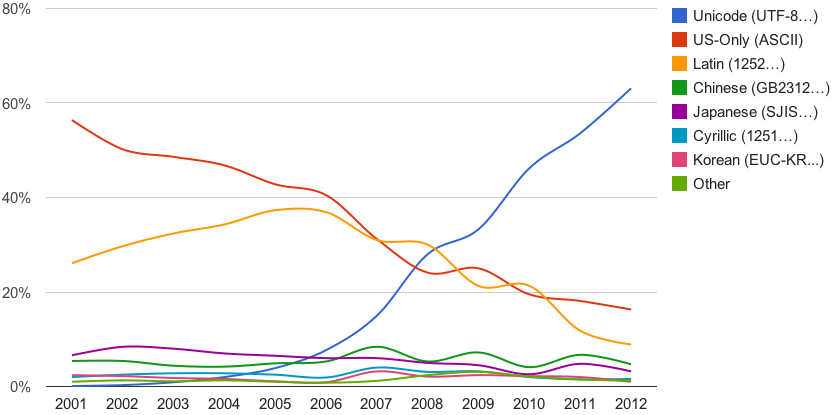
La plupart des compilateurs C permettent d'utiliser UTF-8. Cependant, certaines fonctions de la librairie standard ne marchent plus avec l'UTF-8, étant donné qu'un caractère UTF-8 peut correspondre à plusieurs char :
char s[] = "é"; // chaîne de caractères Unicode
printf("%lu\n", sizeof(s)); // = 3
// é est codé sur 2 char en UTF-8 (donc 2 octets) et \0 sur un octet
strlen(s) // 2 au lieu de 1
3
2
Chaîne de caractères¶
En C, il n'existe pas de type particulier correspondant à une chaîne de caractères. La convention est de définir une chaîne de caractères comme un tableau de char qui termine par \0 (caractère spécial qui sert à savoir quand la chaîne s'arrête). Exemple :
char ex[] = {'e', 'x', 'e', 'm', 'p', 'l', 'e', '\0'};
ex
"exemple"
De façon totalement équivalente, on peut aussi écrire :
char ex[] = "exemple"; // créé un tableau de caractères avec un '\0` final est automatiquement ajouté
Ou d'abord définir le tableau puis modifier ses éléments :
char ex[8];
ex[0] = 'e';
ex[1] = 'x';
// etc
ex[6] = 'e';
ex[7] = '\0';
Tout ce qui a été vu sur le lien entre tableau et pointeur reste valable pour les chaînes de caractères. Ainsi :
- Un
char[](tableau dechar) est automatiquement converti enchar*(pointeur sur le premierchardu tableau) lors d'une affectation de variable ou de passage en argument d'une fonction. - Il n'est pas possible d'utiliser l'initialisation
char ex[] = "exemple";après avoir défini la variable :
char ex[] = "exemple"; // OK dans la définition de ex
ex = "test"; // PAS OK : il faudrait modifier les caractères un par un
input_line_16:3:4: error: array type 'char [8]' is not assignable ex = "test"; // PAS OK : il faudrait modifier les caractères un par un ~~ ^
Interpreter Error:
Il est possible d'afficher une chaîne de caractère avec %s dans printf :
char ex[] = "exemple";
printf("ex vaut %s", ex);
File "<ipython-input-1-21e5b4aef7e2>", line 1 char ex[] = "exemple"; ^ SyntaxError: invalid syntax
Passage de chaîne de caractères en argument¶
Comme dit précédemment, un char[] est converti en char* lors d'un passage à une fonction. Par exemple, la fonction suivante calcule la taille d'une chaîne de caractères (strlen dans glibc):
int size(const char* s) {
int i = 0;
while(s[i] != '\0')
i++;
return i;
}
size("mp2i")
4
Remarques :
const char*signifie "pointeur vers une chaîne de caractères non modifiable (immutable)". Cela apporte une garantie à l'utilisateur : la chaîne de caractères passée en argument ne sera pas modifiée.- Les litéraux de chaînes de caractères (comme
"mp2i") sont de typechar*en C etconst char*en C++. Sisizeavait le prototypeint size(char*)(sansconst), il faudrait donc, en C++, une conversion deconst char*verschar*(size((char*)"mp2i")).
Exercice
Écrire une fonction int count(const char*, char) calculant le nombre d'apparitions d'un caractère dans une chaîne de caractères.
Exercice
Un palindrome est une chaîne de caractères qui peut se lire de la même façon dans les deux sens. Écrire une fonction pour savoir si une chaîne de caractères est un palindrome.
Écrire une fonction copy de prototype void copy(char*, const char*) (cette fonction existe déjà sous le nom strcpy).
Malloc et chaînes de caractères¶
On peut utiliser malloc pour créer une chaîne de caractères sur le tas, comme pour tout tableau :
char* concat(const char* s1, const char* s2) {
int n1 = strlen(s1);
int n2 = strlen(s2);
char* s = (char*)malloc(sizeof(char)*(n1 + n2));
for(int i = 0; i < n1; i++)
s[i] = s1[i];
for(int i = 0; i < n2; i++)
s[n1 + i] = s2[i];
return s;
}
concat("hello", " world")
"hello world"
Exercice
Le codage de César consiste à chiffre une chaîne de caractère en décalant chaque caractère d'une clé k.
- Écrire une fonction
chiffre(char* s, int k)renvoyant un nouveau tableau contenant le codage de César desavec la clék. - Écrire une fonction
dechiffre(char* s)renvoyant un nouveau tableau contenant le codage de César des.